[ ch5. Hash key Rehash & Hash Ring ]
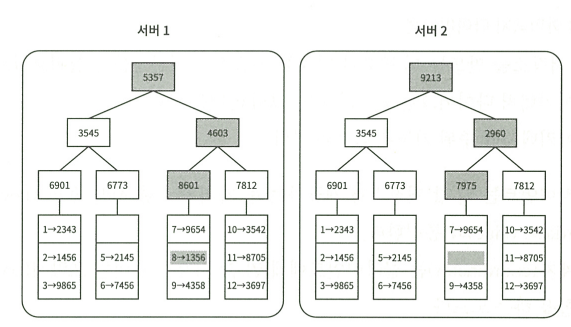
서버를 다중화 하면서 서버의 개수에 따라 해시 값을 serverIndex로 재분배해야함
- 안정 해시 (stable hash) : 시간/위치에 제약되지 않고 동일한 해싱
- 일관성 해시 (consistent hash) : 노드 수가 변경되어도 대부분의 키가 재배치되지 않는 해싱
해시 링(Hash Ring)
- 서버 조회 : 해당 key로 부터 시계 방향에 가장 가까운 서버
- 서버 추가 : 추가된 서버로부터 반시계 기준 다음 서버 사이의 key를 신규 서버로 재배치
- 서버 삭제 : 삭제된 서버로 부터 반시계 방향에 있는 key를 시계방향 앞 서버로 재배치
(즉 key 반시계 방향 탐색 / 서버는 시계 방향 탐색)
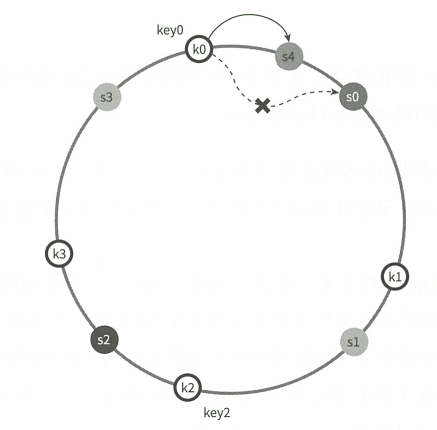
⇒ 결과적으로 삭제와 생성을 반복하면, 서버와 서버 간격 즉 소유하고 있는 key의 개수가 불균등
가상노드 : 한개의 서버가 N개의 가상 노드를 가지도록 설계 (파티션)
- 실제 아래 이미지에서 서버는 S0, S1뿐
- 결과적으로 N이 충분히 크면 key가 고르게 분포 (uniform distribution)
- 생성 및 삭제 메커니즘에서 중복되는 서버의 가상 노드가 붙어있을 경우 무시
[ 6-1. 분산 Key-Value 저장소 ]
CAP 정리 아래 : 3개는 모두 가질 수 없고 반드시 하나를 포기해야 함
- Consistency : 일관성 : 어떤 노드는지 데이터 일관
- Availability : 가용성 : 일부 노드의 장애가 발생해도 계속 동작
- Partition tolerance : 파티션 감내 : 네트워크가 갈려도 계속 동작
👉
CA 시스템?
네트워크 장애는 피할 수 없으므로 CAP 정리에 따라 시스템은 반드시 파티션 감내가 필요!
네트워크 장애는 피할 수 없으므로 CAP 정리에 따라 시스템은 반드시 파티션 감내가 필요!
핵심 기술
- 데이터 파티션 ⇒ Hash Ring 구조 그 자체
- 데이터 다중화 ⇒ 작업 서버 이후 N-1개의 서버에 복제👉매우 중요한 특성
즉 Hash 값을 풀었을 때, S1이 나왔고, N이 3이면 S1, S2, S3만 해당 key를 가짐!
즉, 한 데이터의 소유 서버는 연속적
- 데이터 일관성
- 정족수 합의 (Quorum Consensus) : 1개의 서버를 중재자로 설정하고, 타 서버로 부터 N개의 성공 응답을 받으면 시스템 상 성공으로 간주
- 강한 일관성 (Strong Consistency) : W[쓰기 성공]+R[읽기 성공] > N👉왜 강한 일관성이 W+R>N?
강한 일관성 : 항상 최신의 데이터를 읽는다! (낡은 데이터는 확인 불가)
N = W+R일때 W가 아닌 R이 존재 가능 즉, 크다에서는 N중에 1은 W&R이 반드시 존재⇒ 결국 강한 일관성은 한개의 최신데이터를 보장한다
새로운 요청이 왔을때, N개중에 어떤 서버가 최신 데이터를 가지고 있는지는 어떻게 판별하지?
⇒ 데이터 버저닝!
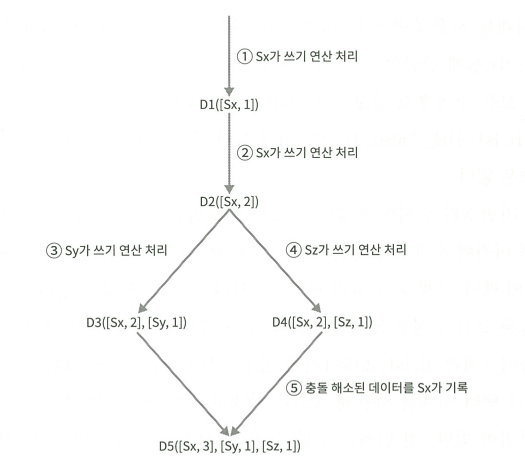
- 데이터 버저닝 (Vector Clock)
- 데이터에 요청을 준 서버 번호와, 버전을 기록
- 버전이 낮으면 최신버전을 쓰고, 버전이 충돌나면 깃허브 충돌 해결 하듯이! (사용자 해결 OR Timestamp 비교)
- 장애 감지
- 멀티 캐스팅 (다중 연결) : 확실하지만, 비효율적
- 가십 프로토콜 (Gossip Protocol)
⇒ 랜덤으로 서버에서 HearbeatCounter와 Time을 기록 / 응답이 없으면 주변 체크 / 장애 노드로 감지
- 장애 처리
- 일시적 장애 처리 : 장애서버의 역할 W/R을 타 서버에 위탁 ⇒ 이후 변경 사항을 일괄 반영👉[Hinted handoff]
⇒ 아래와 같은 Hint(일괄 반영할 데이터 기록)을 큐에 저장하고, 지속적으로 부활 확인{
"target_node": "S2", // 누구 거였는지
"key": "user:123", // 어떤 데이터를
"value": "Alice", // 실제 값
"timestamp": 1723456789123, // 언제 쓰기 시도됐는지
"ttl": 3600000 // 얼마나 보관할지
}
- 영구 장애 처리 : 반 엔트로피 프로토콜 ⇒ 없어진 데이터를 찾고 다른 서버에 복원 👉[Merkle Tree]
- 서버를 버킷으로 나누고
- 각 버킷의 해시를 이용해서 uniform hash 연산
⇒ Hash( key + value + timestamp/version ): 버전이 있어야 덮어쓰기 가능
- 이를 트리형태로 루트노드까지 해싱
- 루트노드부터 값을 비교하면 데이터가 다른 위치를 파악 가능
⇒ 결국 장애가 발생한 서버가 어떤 키를 가져야할지는 백업정보 혹은 키 자체의 serverIndex 연산으로 알 수 있음
- 장애난 서버와 같은 데이터를 덮어쓰기한 이후 N-1개의 서버와 차이나는 데이터를 복구해야하는데 이때 비교를 편하게 할 수 있는게 “Merkle Tree”
- 일시적 장애 처리 : 장애서버의 역할 W/R을 타 서버에 위탁 ⇒ 이후 변경 사항을 일괄 반영