
[ 0. 수직적 규모 확장 vs 수평적 규모 확장 ]
Scale up - 수직적 : 서버의 성능 (고사양 자원)
Scale out - 수평적 : 더 많은 서버
[ 1. 다중화 ]
로드 밸런서
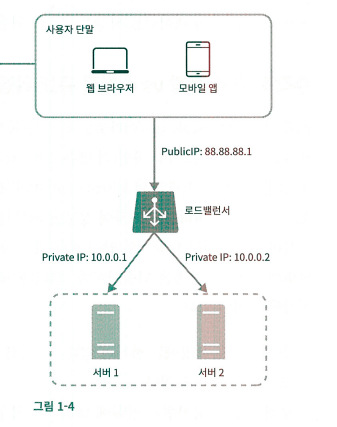
- 클라이언트는 로드 밸런서의 public IP로 접속 (서버 자체와 연결 X)
- 로드 밸런서가 내부 서버들과 연결되는 private IP는 내부 통신만 (인터넷 접속 X)
웹 서버 다중화
- 웹 계층에서는 트래픽 분산 및 고가용성만 신경 쓰면 됨
- 고가용성 (Higfh Availability) : 다중으로 서버를 구성하여 하나의 서버가 다운 되더라도 시스템 전체는 정상 작동되도록
DB 서버 다중화
- 트래픽 분산 및 고가용성 이외에도, 데이터 계층에 대한 처리가 필요
Master-Slave(주-부 다중화 모델) : 원본 + 사본 저장 방식
- 쓰기 연산은 Master에서만 지원
- Master의 수는 Slave의 수보다 적거나 같다.
- query의 병렬 처리률 증가
Master가 다운되면, Slave들에 저장된 데이터가 최신이 아닐 수 있기 때문에 복구 스크립트를 통해 복구해서 slave에 집어넣은 이후, 해당 slave서버를 master로 승격
⇒ 하나의 마스터가 다운되더라도 다른 마스터가 즉시 대응 가능하나,
충돌 관리와 데이터 정합성 유지가 어렵고 복잡
- "누가 누구에게 복제할지"는 처음 구성할 때 미리 설정
- 각 서버는 자기 앞 또는 뒤에 있는 특정 서버 한 곳과 만 복제 관계를 맺음
- 다운되면 그 서버에 복제 데이터를 전달했던 서버를 Master로 승격
[ 2. Latency 개선 ]
캐시(DB 부하 감소)를 사용하거나 CDN을 통해 응답 시간을 빠르게
콘텐츠 전송 네트워크 (CDN)
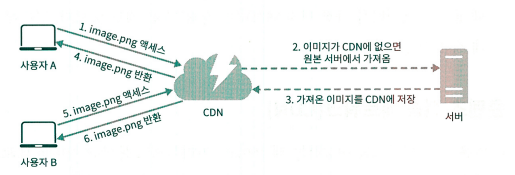
- CDN 서버 : 자주 요청할 거 같은 데이터를 원본 서버에서 가져오는게 아니라, CDN서버에 저장해놓고, 클라이언트가 CDN 서버로 접속하도록 설정
- CDN 서버가 다운 되었을 때, 원본 서버에서 가져갈 수 있도록 구성 필요
- JS 처리 : javascript
<img src="https://cdn.example.com/img/logo.png" onerror="this.src='https://origin.example.com/img/logo.png'">
- Nginx FallBackjavascript
location /img/ { proxy_pass https://cdn.example.com; error_page 502 504 = @fallback; } location @fallback { proxy_pass https://origin.example.com; }
- JS 처리 :
[ 3. 대규모 확장 ]
Stateless - 무상태 웹 계층
세션 데이터와 같은 상태 정보를 웹 계층에서 가지고 있으면, 확장한 새 서버에서는 이용 불가
⇒ DB와 같은 지속형 저장소에서 관리하고, 필요할 때 서버로 전달
- 단순, 안전, 쉬운 확장
다중 데이터 센터 - 대규모 서비스
보통은 geoDNS-routing을 통해 지리적으로 가까운 데이터 센터로 트래픽이 연결
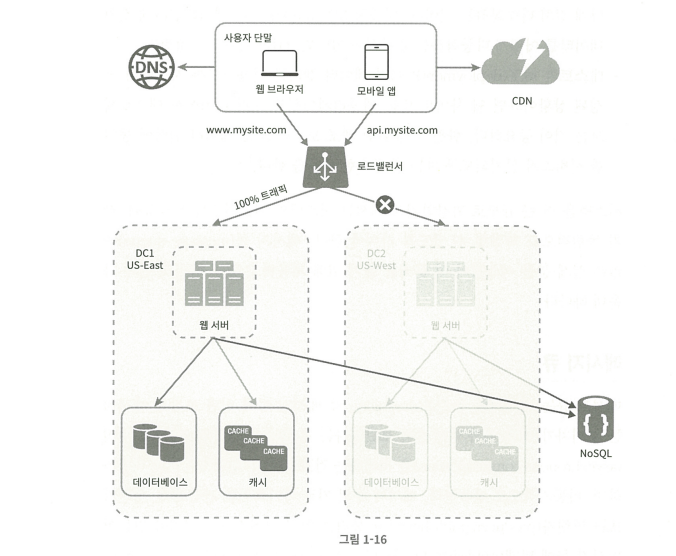
동기 복제 (Synchronous Replication)
데이터 센터에 데이터가 추가되면 연결된 모든 데이터 센터에 복제 완료된 후에 클라이언트에 응답
- 모든 데이터 센터의 데이터가 항상 완전히 동일
- 거리만큼 응답 지연(latency) 발생
- 활용 분야: 금융, 은행 등 정합성이 중요한 서비스
비동기 복제 (Asynchronous Replication)
한 데이터 센터에서 데이터를 먼저 저장하고 응답 이후 백그라운드로 다른 데이터 센터에 복제
- 빠른 응답 속도
- 일시적으로 데이터 불일치 발생 가능
- 활용 분야: 넷플릭스, 유튜브 등 읽기 위주 서비스
[ 4. 메시지 큐 : 서버 간 결합을 느슨하게 ]
MSA : 현재는 모놀리식 구조가 아닌, 기능 별로 분리해서 각 기능별 동작 및 배포 확장이 가능하도록 설계
- 이 때 “결제”서비스가 들어왔다고, “배달”서비스를 직접 호출하게 되면,
- 의존도 높아짐
- 장애 전파
⇒ 직접적으로 연결하는 순간 MSA의 의미가 없어짐
해결책 : 메시지 큐에 넣고, 필요할 때, 이후 서비스들에서 꺼내서 사용
메시지 큐 : 모손실을 보장하는 비동기 통신 컴포넌트
- 비동기적
- 버퍼 역할
동작 과정
- producer가 메시지 발행 → 메시지 큐에 들어감
- subscriber가 구독하고 있는 토픽의 메시지를 알림받고
- 이를 받아서 사용
⇒ producer와 실제 연결 없이, 심지어 producer가 다운되어 있어도, 메시지 수신 가능
⇒ 결과적으로, 생산자와 소비자가 서로의 처리 속도나 규모에 영향을 받지 않음 → 독립적 서비스 동작 및 확장
[ 5. 샤딩 : 데이터베이스의 수평적 확장 ]
shard : 전체 데이터 중에서 일부만 저장된 데이터베이스나 서버 단위
⇒ 데이터를 여러 개로 나눠서 저장 (sharding)
- 샤딩된 데이터는 중복이 없음 (보통 ID를 기준으로 분할 using “%”)
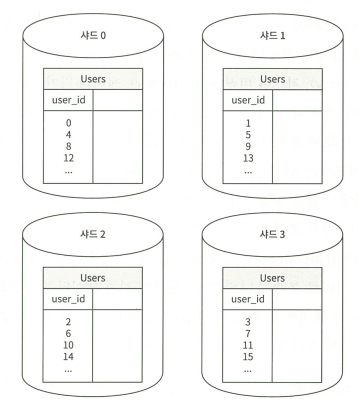
Sharding key(=Partition key) : 각 샤드에 나누는 기준에 되는 키 컬럼 (= user_id)
- 데이터 Resharding : 특정 샤드의 공간소모가 빠를 때, 이를 shard exhaustion이라고 부르고 샤드키 계산 함수를 변경 및 샤드 데이터 재분배
- celebrity problem : 특정 샤드의 일부 데이터가 호출되는 query가 많아, 해당 샤드에 read 연산에 의한 부하가 몰리는 상태
- De-normalization (비정규화) : user라는 하나의 테이블을 샤딩을 통해 나누었기 때문에 조인이 불가능 → 이를 필요한 데이터끼리 묶어 저장하는 비효율적 방식(이미 조인을 진행한 상태로 저장)을 통해 해결
[최종 설계]
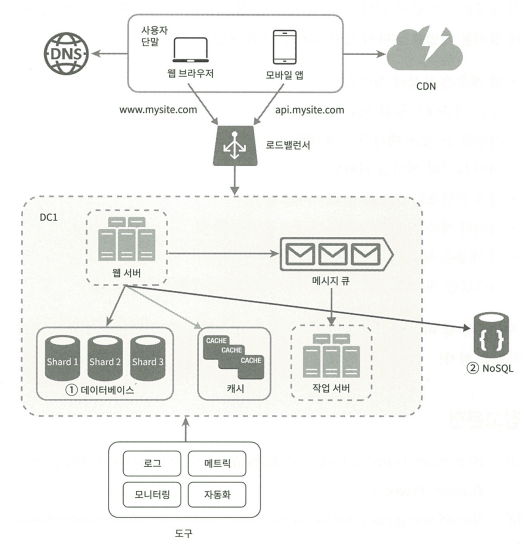
- 로드 밸런서
- CDN
- 데이터 센터 및 DB 다중화
- 메지지큐
- 캐시
- tool